DALL-E won't Let Me Make Pics of Guy Fieri so I'm Self-Hosting Stable Diffusion


AI is the buzz-word of 2023. And rightfully so.
New AI models are popping up every week, new research is coming out and the field is progressing quick.
Last year, I threw Stable Diffusion on an old gaming laptop and let it rip. It was slow, the results were terrible, but it blew my mind. I was generating stupid images of dogs and memes and whatever else I wanted. How was this happening?
The tweet below really put some of the awe I was experiencing into words. A computer can generate images of anything in existence...people, places, things without the internet. You could have a PC running in a hut in the jungle and just generate high-quality photos out of nowhere. WTF.
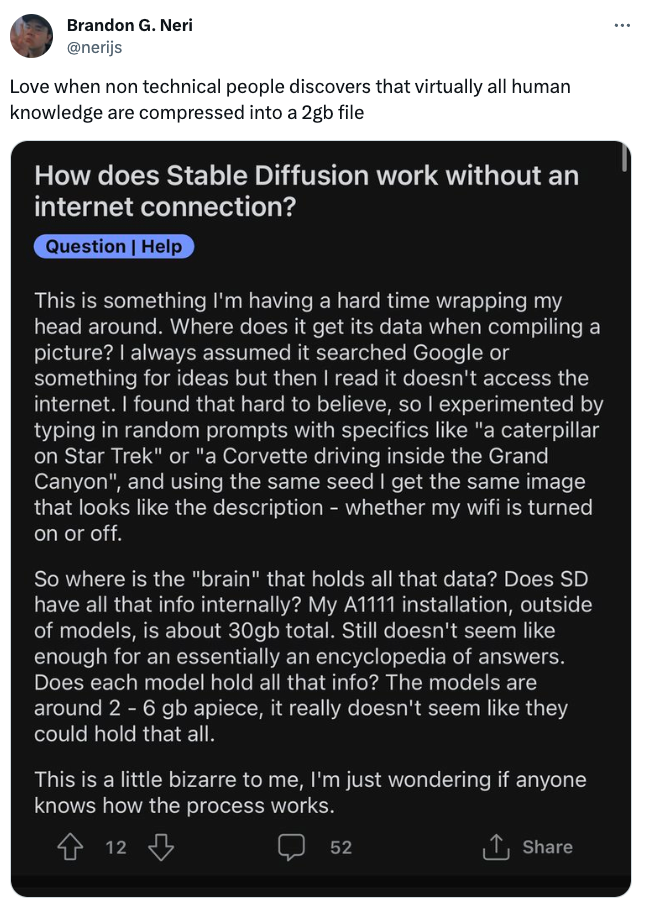
How does this work?
In this post, I'll cover what's going on with some of the larger AI image models today and why I decided to build a beefy computer to learn more about this weird world.
Also check out my previous post about my experiences with Midjourney.
An extremely brief AI Imagery Explainer
AI imagery is complicated.
The tl;dr is that AI models were trained on tons of photos on the internet, labeled with text that describes them and then "trained". This process adds noise to photos in the dataset. Then, the reverse happens, the AI model takes an image with a bunch of noise in it and guesses what it should look like. Or something. I promise I'll research this enough to understand it and write an explainer soon.

If you want to dive deeper into how this work, I'll direct you to this great Paper Explanation video of Diffusion Models and this video by computerphile.
Top AI Image Models out Today
The big 3 AI image generators I'm familiar with today are:
It feels like they're all in an arms-race, cranking out newer and better models and trash talking their competitor's in their whitepapers and flexing how good their models are.
Dall-E 3
DALL-E 3 was announced in late September and then rolled out to Bing and ChatGPT over the next few weeks (Microsoft currently owns an estimated 49% of OpenAI btw). DALL-E 3 might be the best AI image generator out today in terms of prompt accuracy.
You interact with it through Bing Image Generator or a ChatGPT subscription.
You could prompt it with "a nintendo 64 game cartridge, product photo, titled Guy Fieri" and it'd instantly pop out something like this:


DALL-E 3 is accurate. But here's where it got messed up – users started generating offensive imagery with DALL-E. Microsoft didn't like that, so they nerfed it and added a new content policy restricting offensive imagery and copywrited content.
Now users are getting rejected for mundane prompts that make no sense like "tattoos and piercings". You can't even make awesome fake games like Guy Fieri's Cooking Simulator on Nintendo 64.
{kind=link}
For some of the hilarious DALL-E 3 generations, take a look at the Facebook group "Cursed AI" where you can see kermit smoke a cigarette with the band:

Midjourney
Midjourney is the next competitor in the ring and a personal favorite. Although I've canceled my subscription for now, Midjourney has my respect. They're a tiny team and they're moving quickly.
Midjourney is a paid subscription which grants you an amount of image generations. You interact with it though a discord bot, entering commands like "/elden-ring style photo of a pug" and getting a response back from the bot a minute later. I'd rate their prompting second to DALL-E 3 and their image quality as "absolutely insane". Midjourney will also censor certain prompts, but not nearly as much as DALL-E 3.

Stable Diffusion
Stability AI funded and shaped the development of Stable Diffusion along with some researchers in Munich – it's an open-source imagery model you can use for anything you want. Stability AI openly encourages users to have rights to using their generated images, as long as they aren't illegal or harmful to people. Which raises some controversy because Stable Diffusion (and other models) are trained on art and photos from people who did not consent to their work being used.
CEO of Stability AI, Emad Mostaque, says that it's "peoples' responsibility as to whether they are ethical, moral, and legal in how they operate this technology". He argues that there's a net benefit of the technology being in the hands of the public, despite any negative implications.
Stable Diffusion dropped their Stable Diffusion XL model in July of this year and it significantly improved prompting and image quality.
Look at this ugly pug I generated with Stable Diffusion XL. Pretty comparable to the Midjourney one but this one was created on my own hardware. 😎

Although powerful, Stable Diffusion is more complicated than it's competitors and requires more thoughtful prompting. With those complications comes more control.
Honorable Mention: Adobe Firefly
Adobe has open access to their Firefly model and it's pretty good too. They're in Open Beta right now and worth checking out, although more geared towards photography and marketing professionals than people generating images of pugs.
Building an AI Imagery Rig
I cancelled Midjourney because I just didn't use it that much. So I did something stupid and instead paid more money to control my own computer and make my own AI generations.
Why?
I'm kind of obsessed with this stuff. It feels like a once-in-a-life-time type of event, like when the iPhone was released or when KFC decided to use chicken as a bun. Some weird stuff is happening and I want to learn what's happening. We'll consider this hobby a learning and development expense.
Yesterday, I decided to yolo my way over to Microcenter to pick up parts for an AI image generation rig.
I did an hour or two of research and came up with the following rules for my new computer:
- Nvidia is the leader in AI Image Generation
- Get a GPU with a lot of VRAM
You can run Stable Diffusion on AMD GPUs but it doesn't appear to be as easy as Nvidia and not nearly as supported. Nvidia is overwhelmingly the answer for a machine learning rig.
VRAM is one of the bottlenecks for generating AI imagery and holding large datasets. GPUs run in parallel and allow for much faster rendering of images than a CPU might.
Current consumer Nvidia GPUs have somewhere around 6-24 GB of VRAM, depending on how much money you want to spend. You can get away with 6 or 8, but more is generally better.
MSI's marketing team got me because they wrote this great article about the Nvidia 4060 TI and how good it was for Stable Diffusion. It's got 16 GB of VRAM for ~$450. The next option up, the 4090, would run for $1700! I got the last laugh on MSI though, because I purchased an Asus card instead of MSI. Touche, MSI.
There's some nuance here. Although a 4060 TI has more VRAM, cards like the 3090 allegedly can generate images faster. But sometimes they can run into errors about not having enough Vram. I stuck with the 4060 TI.
If you've got any kind of modern-ish laptop or desktop with some spare GPU laying around, (6 GB of VRAM minimum) you can follow along and do this yourself.
Other Specs
I'm not sure other specs matter that much for running Stable Diffusion. 32 gb of ram is plenty. Grab some SSD storage to keep all your HUEG AI models on.
Here's my complete build, 4060 TI, 64 GB Ram and Amd Ryzen 9. I went hard af and I enjoyed every minute. It's compact and lacking some RGB lights which add like 4 GB of VRAM.

Benefits of Stable Diffusion over Cloud Hosting
Why even self-host AI models?
I haven't weighed out the costs of self-hosting Stable Diffusion vs just using one of the many cloud hosted providers out there. Dream Studio was launched by Stability AI, their prices are unclear.
Vast.ai rents GPUs from $0.20-$0.45 an hour. Replicate is $0.81/hr to $20/hr for big hoss GPUs like the A40. Services like GPU-mart rent GPUs for $200/mo minimum.
(Side note: Did you know the US has blocked the sale of powerful GPUs to certain countries? Wild.)
If you use a GPU service that bills by the hour, you can mess around with Stable Diffusion for cheap. I don't think you get the same control and pride as self-hosting though. And to be honest, I'm kinda pissed about DALL-E 3's content policy now. Who are they to give us the ability to generate Guy Fieri Nintendo 64 games and then just rip it away. Heartless.
Let's get to it.
How to Self-Host Stable Diffusion
After feeling the joy of building a computer and troubleshooting some weird BIOS bug, I was off to grab me some o' dat organic, home-grown AI image generation.
Setup was easy. You can get up and running in an hour or less with Stable Diffusion. You'll probably spend the rest of the night playing with it, though.
"Automatic1111" is the most popular way to run Stable Diffusion locally. It's a web interface that allows you to write prompts and get imagery back. Simple! Sorta. There's a lot of tunable knobs and bells and whistles.
Here's how to do it on Windows:
- Update Nvidia Drivers
- Install python 3.10.6 (as of today's date, this is the recommended version)
- Install Git
- Clone the repo at https://github.com/AUTOMATIC1111/stable-diffusion-webui (read the docs there too)
- Run
webui-user.batfrom Windows Explorer as a non-admin, user.
Once you've done all that, your terminal will pop out a url to visit and see the Automatic1111 interface at localhost:6870
One more thing! We need models to run! Stable Diffusion XL, or SDXL 1.0 has two models: a "base model" and a "refiner" model. You don't need the refiner, but it can help image quality. The base model does the image generation and then the refiner comes in after and does some cleanup and stuff.
- Go here to download SDXL base 1.0
- Click the download icon next to "sd_xl_base_1.0.safetensors"
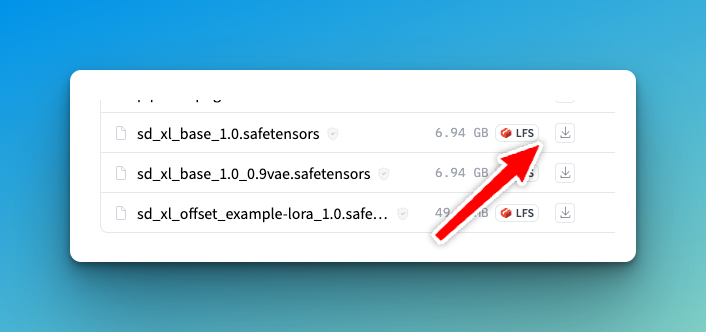
If you want the refiner, do the same thing here, grabbing "sd_xl_refiner_1.0.safetensors".
Once your new models have downloaded, move those bad dawgs to your automatic1111 installation folder under stable-diffusion-webui/models/StableDiffusion:
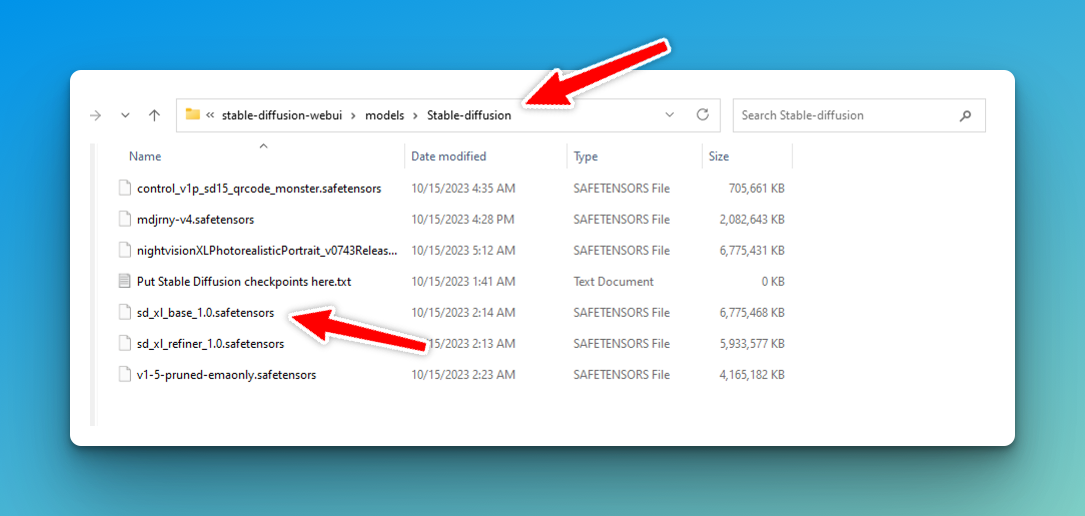
Back to your Automatic1111 web interface:
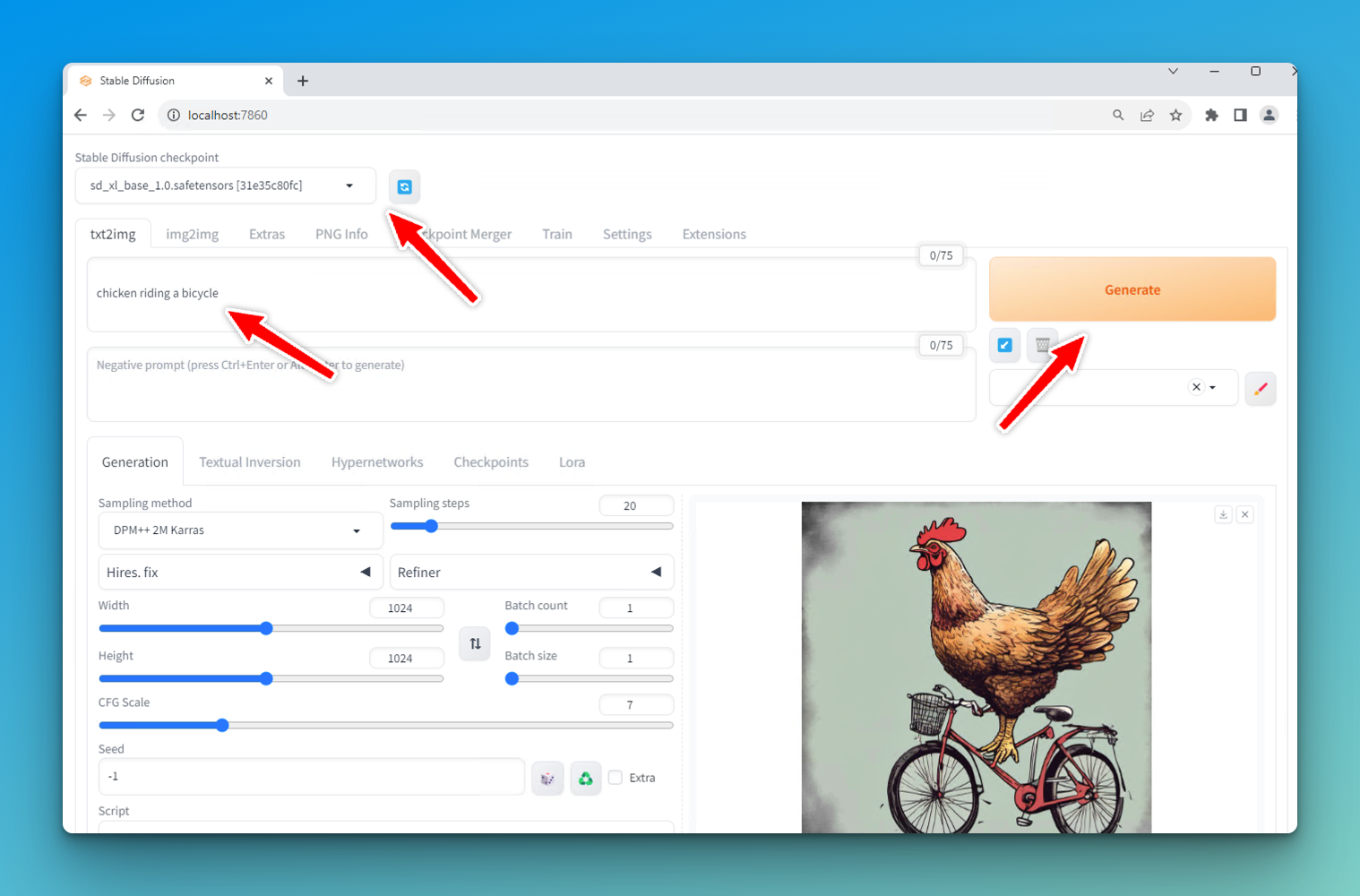
For now, there are like 6 important things here:
- The CheckPoint Or Model: This is where you'll specify the Stable Diffusion XL1.0 model we just downloaded and moved. Hit the refresh button if the drop-down doesn't show your model.
- The prompt box under txt2img. This is the thing you want to generate an image of. Prompting is another topic, but my advice is to be descriptive, use commas and describe the scene in detail.
- Sampling Steps: More sampling steps will give you better image quality at a slower speed. Lower sampling will give lower quality quicker.
- Image Width and Height: I get terrible results with 512 x 512, so I just use 1024 x 1024.
- Refiner: If you grabbed the refiner, open this section and select it. You can enter -1 here to skip the refiner. Test with and without it.
- The Generate Button Click this once you're ready to rock.
If all went well, you'll have an image of a Chicken on a Bicycle, or whatever you prompted. The one above generated in a mere 13 seconds. Deeecent.
Automatic1111 has a ton more features, like an extensions system that developers can make plugins for and an API to interface with. Read up on some of the other features and play around. It's great.
Other Stable Diffusion Interfaces
There's a few other alternatives to automatic1111, like ComfyUI and others, which boast even more control and features. I haven't tested them, but you should know they exist.
Fine Tuning Models with a LoRA
Just when you thought we were done, I'm here to sell you the DLC: LoRA.
LoRA, or Low-Rank Adaptation is sorta like a new model that adds on top of your base model. It's a smaller file, around a couple hundred MB and gives your Stable Diffusion install the ability to generate specific characters or styles.
There's a couple fun ones, like Super Cereal, which generates Fake Cereal Box Art:

Another, by the same artist can make Ikea instructions:
One LoRA model does pixel art:

LoRAS are trained on a set of images (somewhere from 10s to 100s) and allow you to pull that style into your model. You could even take a bunch of pictures of yourself and generate an image of yourself hanging out with aliens or make a mugshot, LinkedIn photo, whatever.
One thing I'd like to experiment with is scraping eBay listings for Nintendo 64 cartridge photos and training my own LoRA so I can generate more Guy Fieri Cartridges.
There's also services and apps online that sell access to AI models trained on your face to generate "AI Headshots".
How to Use a LoRA in Automatic1111:
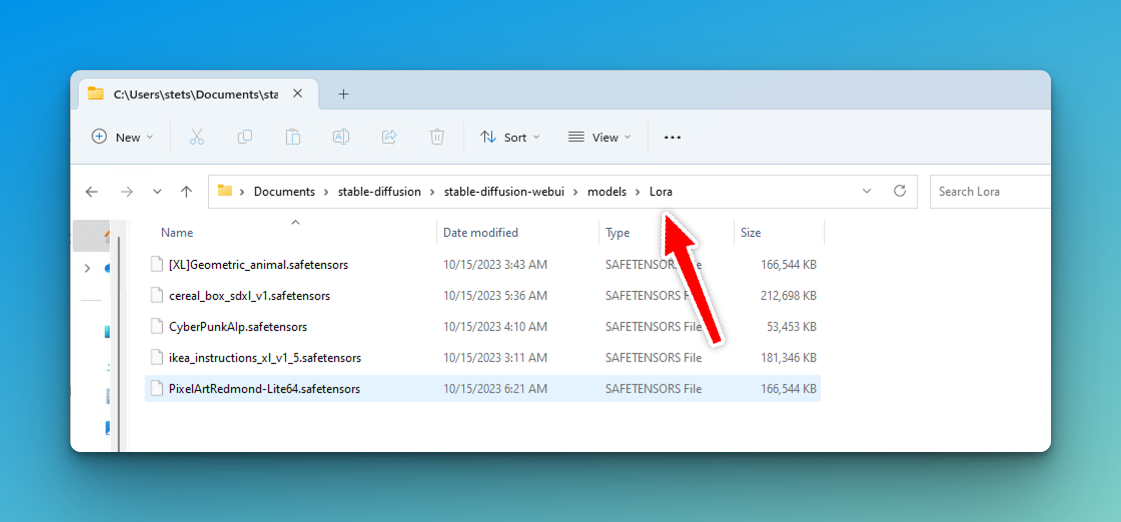
- Download the LoRA model from Hugging Face or another provider
- Drop it in your stable-diffusion-webui/models/Lora folder
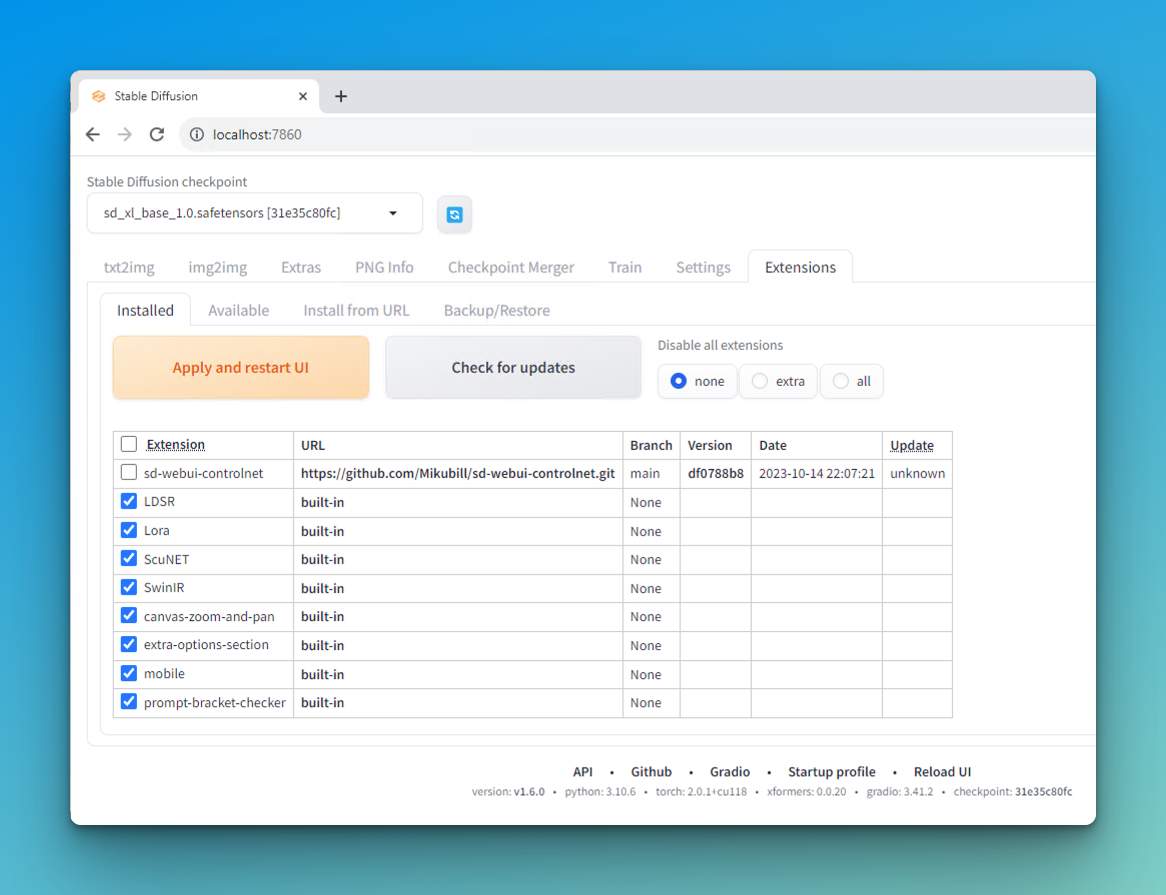
- Go to Extensions> Installed and ensure you have LoRA checked
On txt2img> Lora, click on the LoRA model and it'll populate in the prompt like "<lora:cereal_box_sdxl_v1:1>". (The number after it is the weight, and determines how heavily the LoRA impacts the generation ).
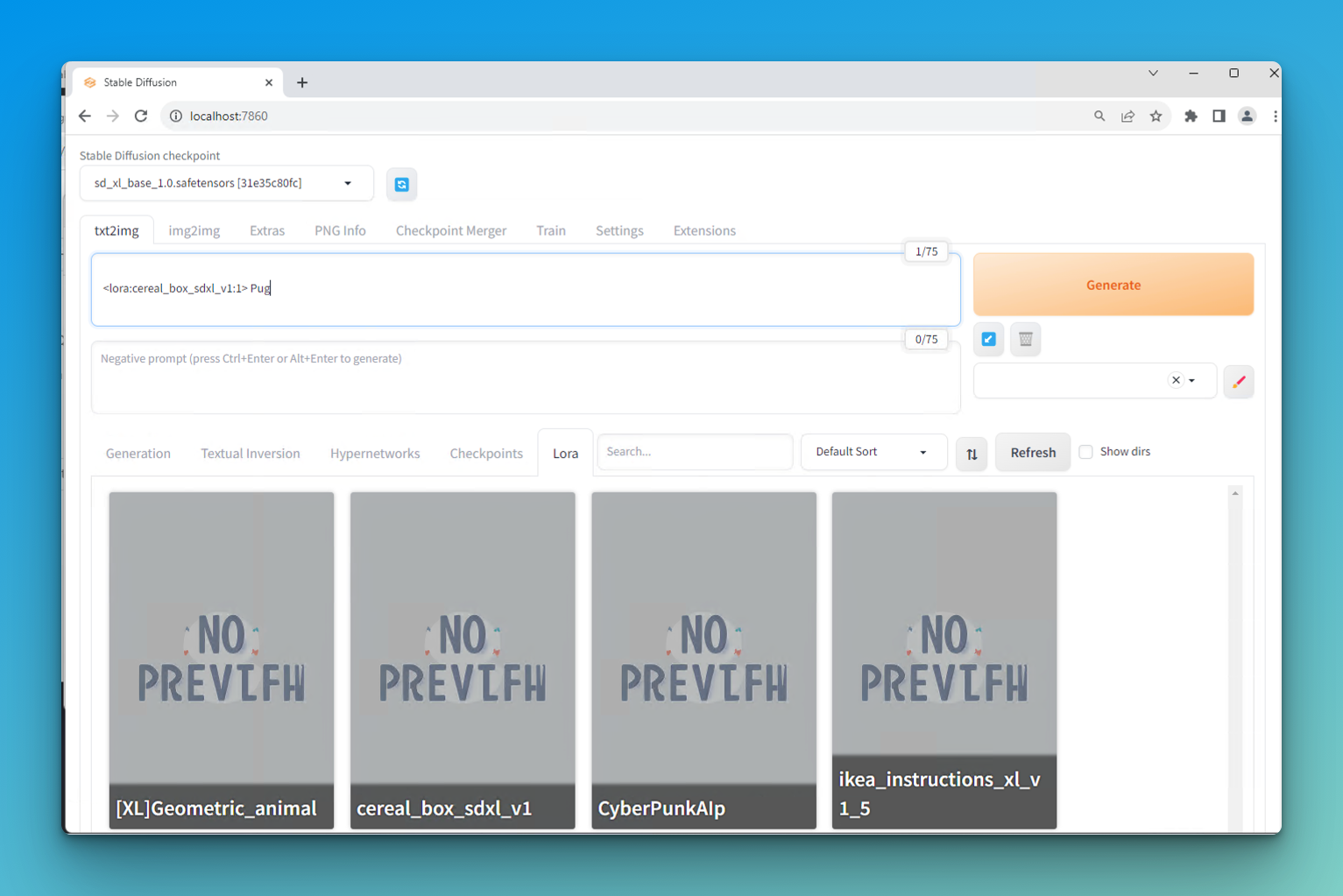
Put your prompt after that and smack Generate!
Go back to the Generation tab and view your masterpiece:

What about LLMs?
LLMs, or Large Language Models are a whole 'nother category of AI generated content. You're familiar with ChatGPT, but did you know you can also host your own LLM?
I haven't done this myself yet but I will soon. A good place to start is the LocalLlama subreddit. The steps should generally be the same as AI imagery: download a web interface like text-generation-webui, download models, ???, Profit!
Tons of LLM models are coming out lately. Facebook released their Llama 7b dataset, which is available on Hugging Face. Stability has their own LLM. Mistral 7b just came out. The interface is like ChatGPT but runs on your own system.
Additionally, you can also extend LLMs and train them on your own data. This would allow someone to have a conversation about that dataset. I think this'll be a huge deal for organizations who value data privacy and can unlock additional products, features and insights with their proprietary data.
What can actually we do with AI imagery?
Most of my value from AI image generation has been in having fun and learning. That's my motivation. I like making funny images and sending them to friends, laughing when the model didn't make what I intended. There's a crazy rush for me to make art at the speed of thought, no matter how juvenile it may be.
There are other implications. Stock Photo companies are in a weird place. Pivot or die? Artists are kind of being taken advantage of and their jobs are changing (aren't they all?). Online images can't be trusted. We'll have to develop some weird cryptographic signature to verify authenticity. Information warfare will develop further.

I'm just a n00b to this stuff still, this article probably has inaccuracies and it barely scratches the surface. I don't hardly understand any of it. But I'm having a hell of a time.